Member-only story
Efficient Parallel Prefix Sum in Metal for Apple M1
Comparison of optimal M1 GPU scan primitives to vectorized CPU performance
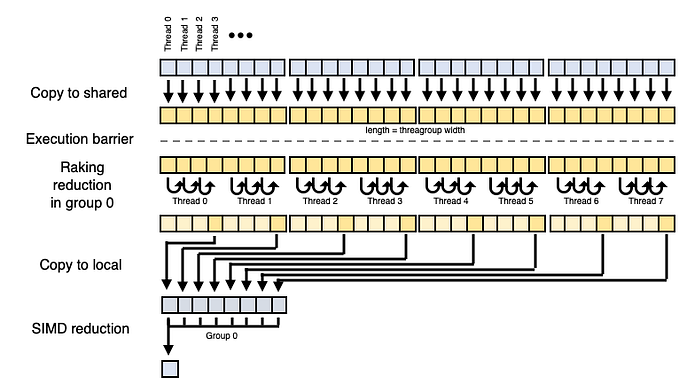
In my last story, Optimizing Parallel Reduction in Metal for Apple M1, we explored several strategies for maximizing throughput in parallel reduce on the M1 processor. Given the low arithmetic intensity of reduction, we could optimize kernels that ran at the memory bandwidth limit regardless if the kernels were tuned to maximize parallelism or cost efficiency. This story will explore a more complex optimization problem, parallel prefix sum.
All prefix sum, or inclusive “scan,” is common data parallel primitive that finds use in sorting, stream compaction, multi-precision arithmetic, among many other uses. The operation is so common that it is in the C++ STL and is built into several languages. The scan operation takes a sequence of values [x0, x1, …, x(n–1)] and applies a binary operator ⊕ to yield a second sequence of values [x0, (x0⊕x1),…,(x0⊕x1⊕…⊕x(n–1))]. For example, a scan with the binary operator plus on the sequence [0,1,0,0,1,0,1] yields a cumulative sum in the second sequence [0,1,1,1,2,2,3].
A related and perhaps more common operation called “prescan” or exclusive prefix sum shifts the inclusive sequence one to the right and inserts an identity value I at index 0 (I = 0 with the plus operator), [0, x0, (x0⊕x1),…,(x0⊕x1⊕…⊕x(n–2))]. The sequential computation of scan can be trivially computed by result[i] = input[i] ⊕ result[i –1]. Thus, the total number of operations required is n–1, where n is the number of values in the sequence, and so the scan requires O(n) time.
While scan appears inherently sequential because each value depends on a prior value, there is a significant pool of literature on the parallelization of this primitive. Hillis and Steele reported an early algorithm based on the Kogge-Stone adder that, despite requiring more additions than the sequential algorithm, maps well onto the simdgroup (warp) execution model of modern GPUs because of its step-efficiency. Blelloch reported a work-efficient tree-based algorithm based on the Brent-Kung adder that was commonly used prior to the rise in popularity of SIMD execution models on GPUs.